本地优先 (Local First),指的是类似 google doc 这样一种应用,网络连接正常的时候可以多人协同编辑一份文档;而网络中断的情况下,每个参与者还是可以正常的编辑文档,软件的功能基本不受影响,只是期间看不到其他协作者的修改;等到网络连接恢复,会自动同步并合并多个参与者期间对文档的修改。
当然对于开发者来说,还有一个更加熟悉的例子,那就是 git 。
Local First 有很多优势:可用性高,离线状态也可以继续使用;安全,本地保存数据;隐私,只传递必要的交互数据。
更详细的描述可以参见: 不要在云上保存你的数据(一):本地优先的七个理念和不要在云上保存你的数据(二):未来软件发展途径。
区块链系统的节点之间也是一种本地优先的关系。
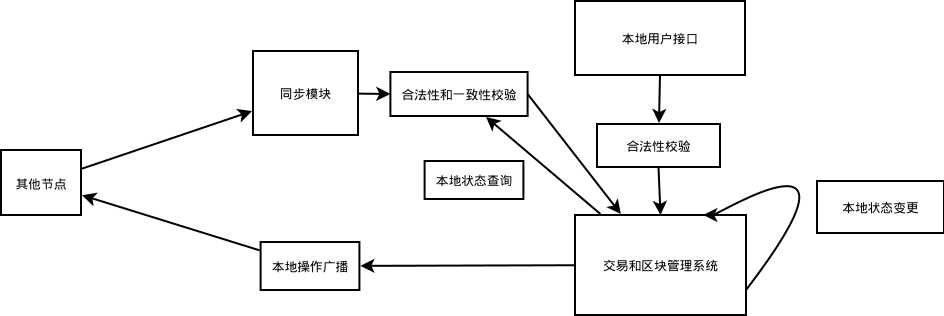
- 区块链设计模式系列(一)对等网络里提到,区块链的每个节点地位是对等的,每个节点都可以处理用户的请求,也都可以出块。因此,节点需要处理的内容,不管是交易,还是区块,都有两个来源:本地的,来自其他节点的。
- 对于来自其他节点的内容,出于安全的考虑需要做严格的合法性检查。但是检查通过之后,后续处理过程,跟本地的数据处理是一样的。这里的检查可能是依赖本地状态的,跟本地状态有冲突的数据都会被抛弃。整体上有点
merge操作的味道。 - 节点间似断似连。在共识阶段之前,比如交易池和未确认的链,节点都是以本地状态为基础来操作的,可以说各个节点在不停的分叉。然后通过
merge来自其他节点的内容,在一定的时间延迟之后,趋于一致。