
跑了一阵子CITA测试网,磁盘满了,然后就停掉服务了。这里说一下处理经验:
背景
服务器有两个盘,一个系统盘,100G,一个数据盘,200G。但是如果链的出块时间很快(1s 一个块),运行时间久了,测试的交易等很多的话,就会导致磁盘不够。然后节点就处于一个不正常的状态(虽然节点的程序没有停,但是不能出块)。可以看到,可用空间是 0 B,很多需要创建临时文件夹的命令都不能使用了:

找到原因
系统盘是什么在占用磁盘:
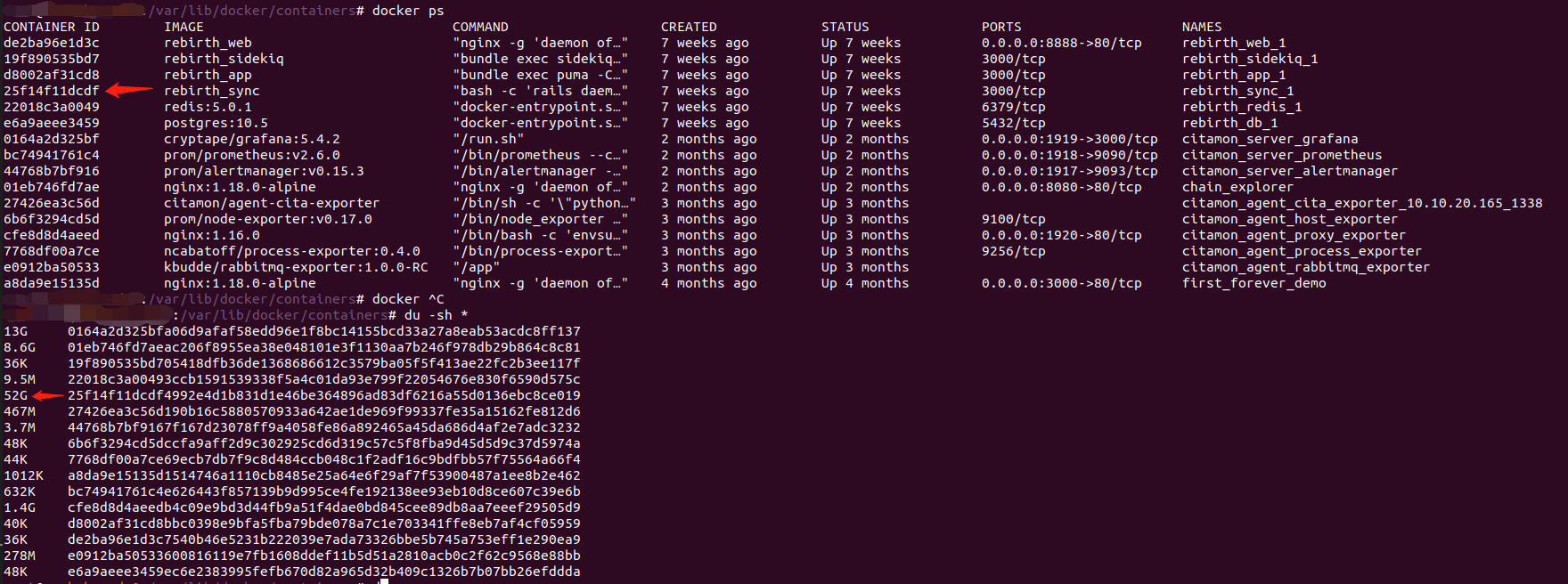
因为 CITA 链的很多组件都使用docker,最后发现是 container 占用比较多,可能是 docker 自带的 log 等。
解决问题
关闭 rebirth
因此只需要 rebirth 的 docker 服务就能释放非常多的磁盘。
这一步是必须的,这样才能执行接下来的操作,不然无法执行部分命令。
扩展系统盘到 200 G
阿里云控制台里面先将系统盘扩容到 200G。
然后再进入服务器 terminal
先查看磁盘情况:
fdisk -lu
再查看文件系统情况:
df -Th
因为我们系统是 type 是 Linux,所以是 MBR 格式,所以配置步骤是:
# apt install cloud-guest-utils
# growpart /dev/vda 1
# resize2fs /dev/vda1
resize2fs 1.44.1 (24-Mar-2018)
Filesystem at /dev/vda1 is mounted on /; on-line resizing required
old_desc_blocks = 7, new_desc_blocks = 13
The filesystem on /dev/vda1 is now 52428539 (4k) blocks long.
配置的详细信息可以参考: https://help.aliyun.com/document_detail/113316.html
解决文件描述符过多
推测因为之前磁盘不够,监控组件的 agent 在写入磁盘失败后不断尝试,导致的。
然后重启 monitor 的 agent 组件就好了
重启服务
最后再启动 rebirth,链的节点,monitor 的 agent 服务等
