
在前两期中,秘猿小课堂给大家分享了构建高性能区块链内核 CITA 背后的思考。这一期,我们深入研究 CITA 是如何进行性能优化,并且将交易处理的性能达到 15000 TPS量级。有个好消息,CITA 将会有个大新闻,敬请期待~
秘猿科技区块链小课堂第 6 期
在区块链的设计中,有一个「不可能三角」的说法,即安全、去中心化、性能,这三者只能取其二。Nervos 是用分层设计来解决不可能三角问题。在底层 Layer1 里,CKB 就选取安全和去中心化,Layer2 选性能。Layer2 追求把性能做到极致,去中心化和安全由 CKB 来解决。
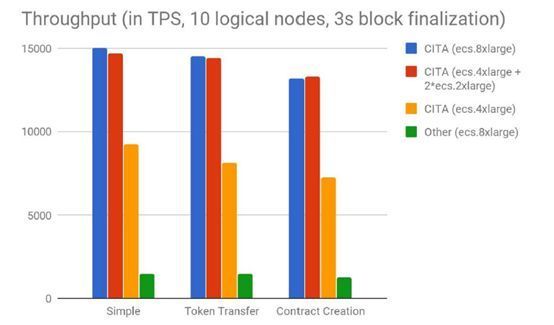
CITA 作为支持智能合约的区块链框架,有非常良好的性能表现,交易处理的性能可以达到 15000 TPS[1],非常适合作为 Layer2 的高性能区块链解决方案。本文将会简要讨论秘猿科技是如何对 CITA 进行性能优化的。
微服务架构
传统的公有区块链往往采用整体式架构。因为需要考虑去中心化,就需要考虑节点可以在普通硬件上可以执行,而在架构设计上无法兼顾性能。CITA 作为专门面向企业用户设计的高性能许可链(许可链可以是联盟链,也可以是公有许可链),采用微服务架构,可以更好的利用服务器集群,而不是使用单一机器运行节点。这样可以充分利用硬件的优势,节点不再是一个物理概念,而是一个逻辑概念。

CITA-BFT
传统的 PBFT 类算法中,一般使用三阶段协议 prevote、precommit、commit ,以 Tendermint 为例。

Commit 阶段主要是为了 Proposer 向其他节点再广播一轮 BlockProof,使得所有节点统一投票。但是实际上在 Precommit 阶段,各个节点已经收集足够的投票,只是投票集合可能不一致。比如对于 ABCD 四个节点,A 可能收到 ABCD 的投票,B 只收到 BCD 的投票。由于投票属于 Block 的一部分,也需要共识,为了保证节点统一投票,所以由 Proposer 再进行一轮广播。
在 CITA-BFT 中,我们优化了 Commit 阶段。在区块链中,Block 的共识是一个连续的共识。所以,我们可以将当前 Block 的 Proof 放到下一个块的 Proposal 中,这样可以在下一个块的 Prevote 阶段对上一个 Block 的 Proof 进行统一,不再广播共识后的 Block。
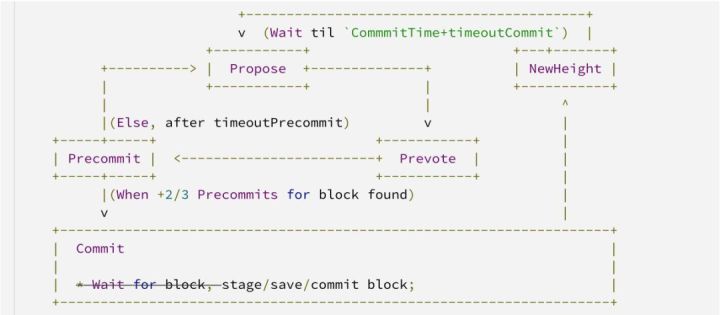
这样做的优点有两个:
减少了一轮消息的广播,缩短了共识时间,并且减少了网络的负担。
传统的 PBFT 类共识算法在 Commit 阶段,如果 Proposer 发送掉线等情况,会需要额外的一轮进行共识,而在 CITA-BFT 则不会发生这种情况。
Proposal 预处理
在传统的 PBFT 类共识的区块链中,共识和交易的处理都是串行的。在共识 Block 的过程中,Executor 是闲置的。共识完成之后,将新的 Block 发送给 Executor 处理,Consensus 等待 Executor 处理完之后才能进行新的高度的共识,此时 Consensus 模块是闲置的。待 Executor 处理完 Block 之后,发送最新的 Status 之后,Consensus 才进行新高度的共识。
在实际的共识过程中,节点在 Prevote 阶段收到 Proposal 并验证之后,Proposal 就有很大可能变成最终 Commit 的 Block。在网络情况正常的情况下,通常一轮共识即可完成当前高度的 Block,此时如果提前对 Proposal 中的交易进行处理,则在共识流程中的后半部分则和交易的执行是同时进行的。当 Executor 处理完之后,等待 Consensus 发送已经确认的 Block,此时 Executor 只需要判断此 Proposal 是否是共识的 Block。如果是,则直接将处理结果进行 Finalize,并通知 Consensus 进行新高度的共识;如果否,则重新处理,这种情况和没有预执行的流程是一致的。
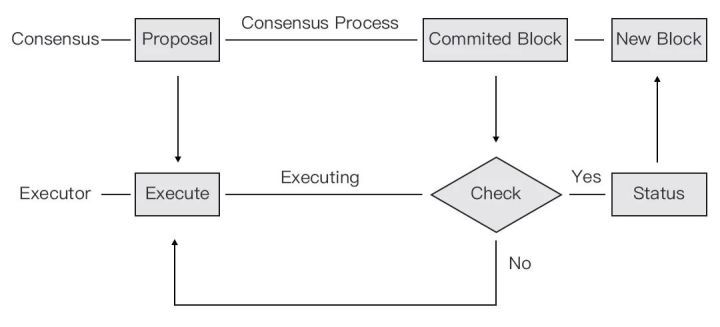
这样在多数情况下区块都能提前处理,将交易处理的时间提前。即便在较坏情况下,进行多轮共识时,Proposal 也可以按照时间戳进行比较,打断当前正在进行的预处理,执行更新的 Proposal。在最坏情况下,没有收到 Proposal 或者收到错误的 Proposal,Executor 也和原来的共识流程相同,在收到 CommitedBlock 之后,进行交易的处理,并没有任何性能上的损失。
缓存
在性能优化中,缓存是一种常见的手段,同样在 CITA 中也存在大量缓存,来解决性能问题。
签名验证缓存。通常交易签名的验证比较耗时,对于已经验证通过的交易,根据其 Hash 将验证结果进行缓存。这样如果节点再收到同样的交易(可能是用户重复发送或者从其他节点转发)时,则可以命中缓存,减少验证签名的时间消耗。
区块信息缓存。对于在交易处理过程中,或者用户查询操作中,经常会需要查询 Block 或者 Transaction 等信息,可以将此类信息缓存,这样能大大提高查询的效率。
在交易处理过程中,需要从数据库中读取之前的 State,而 MPT 的查询路径比较长,需要多次 DB 的查询,非常耗时。在 CITA 中,会将经常使用到 Account 进行缓存。
通过缓存技术,大大减少了交易验证和处理的时间。
消息通信
在微服务架构中,由于服务的拆分导致各个微服务之间消息通信比较频繁,这样消息中间件非常容易成为瓶颈。一方面,由于我们使用了微服务架构,消息中间件本身可以单独部署,可以通过提高硬件能力进行纵向扩展,也可以通过集群的方式进行横向扩展。
除此之外,我们还对微服务之间的消息进行优化,来提高微服务间通信的效率。
消息压缩。例如在压力比较大时,Block 中往往有上万笔交易,这样消息会非常大。因此我们采用了消息压缩技术,在消息超过一定大小时,会对其进行压缩,这样减少消息中间件的压力,同时也减少了传输量,提高了传输速度。
减少不必要的消息。例如,在 Consensus 服务收到 Proposal 时,需要对其合法性进行验证。由于其可能包含大量交易,会导致传输量很大。因此在 Consensus 可以先验证交易的 Hash 是否正确,再将 Proposal 的其他信息和交易的 Hash 发送给 Auth 模块即可,而不用将整个交易发送给 Auth 模块。
打包发送。将消息打包,也是一种比较常见优化手段。比如在 RPC 模块中,需要将交易发送给 Auth 模块进行验证,在压力比较大的时候单个消息发送则消息数量会非常大,此时 RPC 会将消息进行打包后再发送给 Auth 模块,可以大幅度的减少消息的数量,从而减少消息中间件的负载,提高消息的发送速度。
Static Merkle Tree
在 Bitcoin 中,为了解决轻节点的交易验证问题,引入了 MerkleTree。但是 Merkle Tree 的每个节点的产生都要计算一次 Hash,而 Hash 计算非常耗时。
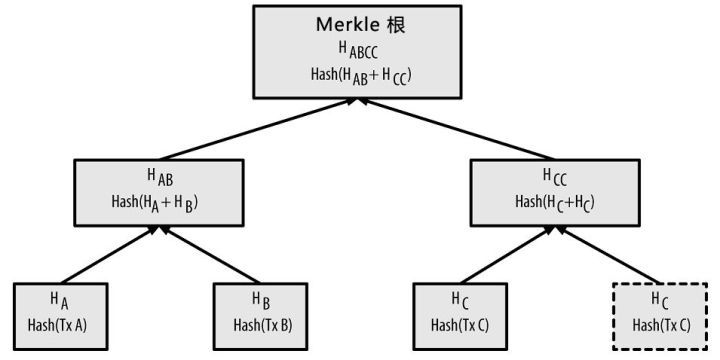
大家注意到最后的叶子节点 Hc 是直接复制了 Hc。这样是因为 Bitcoin 和 Ethereum 中交易是依次加入到 Merkle Tree 中,可以递增地去构造 Merkle Root。比如节点当前的 PendingBlock 中有交易 TxA、TxB、TxC、TxD,当前的 Merkle Root 是 H(ABCD)。新交易来 TxE 来了之后,计算 H(EE),再向上计算,这样原有的 H(ABCD) 部分不用再计算。
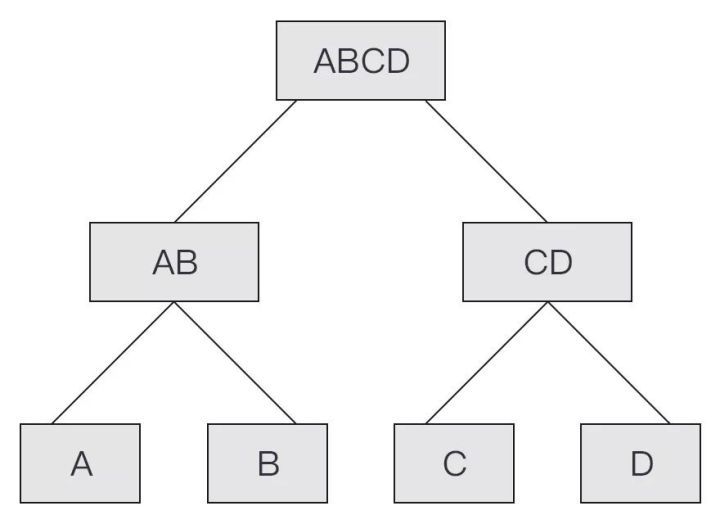

当交易 TxF 来了之后,替换掉最右边的 TxE,再依次向上计算 root,这样只计算一部分就可以了。之前的 H(ABCD) 部分不用再重新计算。
在 CITA 中,交易会先经过 Auth 验证进入交易池,然后由 Consensus 一次性选取交易打包后共识,最后再由 Executor 处理,同时将处理后的结果 Receipt Root 存入 header 中 。由于是先共识交易内容然后再计算交易的结果,所以 Block 中的交易的处理结果 Receipt Root 顺序已经完全确定,不会再发生修改了。由此我们可以将所有 Receipts 一次性算出其 Receipt Root,而不用考虑其动态计算的过程。由此我们可以优化 Receipt Root 的计算。
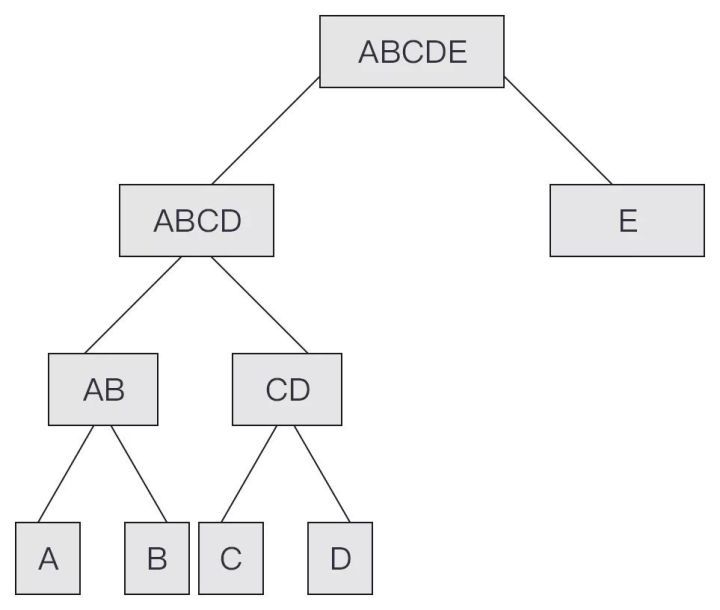
对比 Bitcoin 和 Ethereum 中的 Merkle Tree,会发现由于没有奇数节点的复制,节点 E 这里的 Hash 计算会减少。我们称这棵树为 Static Merkle Tree。
另外,在 Ethereum 中每笔交易都会产生新的 State Root,而 State Root 的计算又是非常耗时的。因此在 CITA 设计之初,交易计算完之后,只会将其状态更新到 Account Model 中,而不会将其变更更新到 State 的 MPT 中。只有在整个 Block 计算完成之后,才会将所有的计算结果提交到 State 的 MPT 中并计算 State Root,这样大大减少了 MPT 的操作和计算。在 Ethereum 最新的设计中也采用了同样的方案。
签名验证
当前 Bitcoin 和 Ethereum 都采用了 secp256k1 的签名算法,在交易验证中,签名的验证尤其消耗 CPU 资源并且耗时。CITA 支持多种签名算法,默认采用 secp256k1。在笔者的电脑(Thinkpad 470p i7-7820HQ)上简单的转账交易的签名验证速度大约为 3000 多每秒。Auth 模块提供了交易的并行验签,这样可以充分发挥硬件的优势,提高系统的验签速度。
除此之外,CITA还实现了 Ed25519 签名,相比 secp256k1 性能更好,并且在安全性方面也更有优势,用户可以根据个人需求选择自己想要的签名算法。我们性能测试的 15000 TPS 的数据指的是 secp256k1。
异步处理
在软件设计中,异步处理通常也是比较好的性能优化手段。除了前文提到的交易预处理,在 CITA 中的其他模块中也存在一些这样的设计。比如在 Executor 中,Block 执行完成之后,需要将最新的 State 保存到 DB,而一旦 State 状态变更比较多时,此操作将比较耗时。由此,Executor 提前将 Status 发送给其他模块,然后再到 DB 进行存储。当然可能会在存储失败时导致异常情况,因此在 Conseneus 会保存最新的几个 Block,来防止其他微服务内存储失败的特殊情况发生。
批量交易
另外,CITA提供了批量交易的接口,用户可以组装多个交易数据,共享同一个签名。这样原来的多个交易就变成一个交易,减少交易存储和签名验证,加快交易的处理,同时也降低了用户发送交易的手续费。例如用户 A 需要调用 N 个不同的合约,原来需要发送 N 笔交易,通过批量交易的方式,可以将合约调用的 data 按照既定格式拼装在一起,然后再进行一次签名发送到批量交易合约,合约再将 data 解析成多个合约调用。
当然批量交易只能算作一笔复杂的组合交易,只完成了一次正常交易的处理流程,因此在性能测试中只能算作一笔交易。CITA 在性能测试中并未采用此手段。
Rust
CITA 中绝大部分代码是用 Rust 语言实现。Rust 语言的极小运行时,与 C 语言媲美的优异性能,也是 CITA 良好性能的一大保证。作为国内最早使用 Rust 的团队,从 2016 年开始至今也在和 Rust 一同成长。 Rust 语言的其他特性:保证内存安全,基于 trait 的泛型,模式匹配,类型推断,高效 C 绑定等等,也极大的提高了我们的开发效率。
未来我们还会在微服务架构改进,网络层,Block/Transaction 广播,状态存储,硬件加速,VM,并行计算等等各个方面做更多研究,将 CITA 性能提上一个更高的水平。